首先,先從比較常見的機器學習方法開始,也就是隨機森林方法,幫大家快速講解一下大概(因為主要目的是在寫Algorithm),但要講隨機森林要先講決策樹
一、甚麼是決策樹: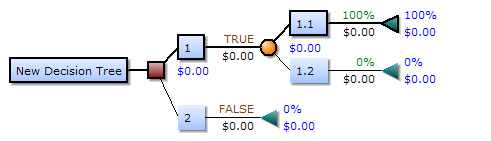
(來源:維基百科)
決策樹基本上是一個用來做決定的模型,就好比說你今天在思考要吃甚麼時候,你會考慮預算,口味,位置…而這些就會是自變數(就是所謂x),而你決定要去吃甚麼就是應變數(也就是我們想要求到y),而決策樹就好比你對x去做條件EX:我要吃東西,首先如果位置是我首要考量,在我家距離500公尺內作為條件來區分吃的東西,再來可能是口味部分可能用鹹淡口味來做為區分,而一個一個條件下來,你就會有一顆決策樹,如下: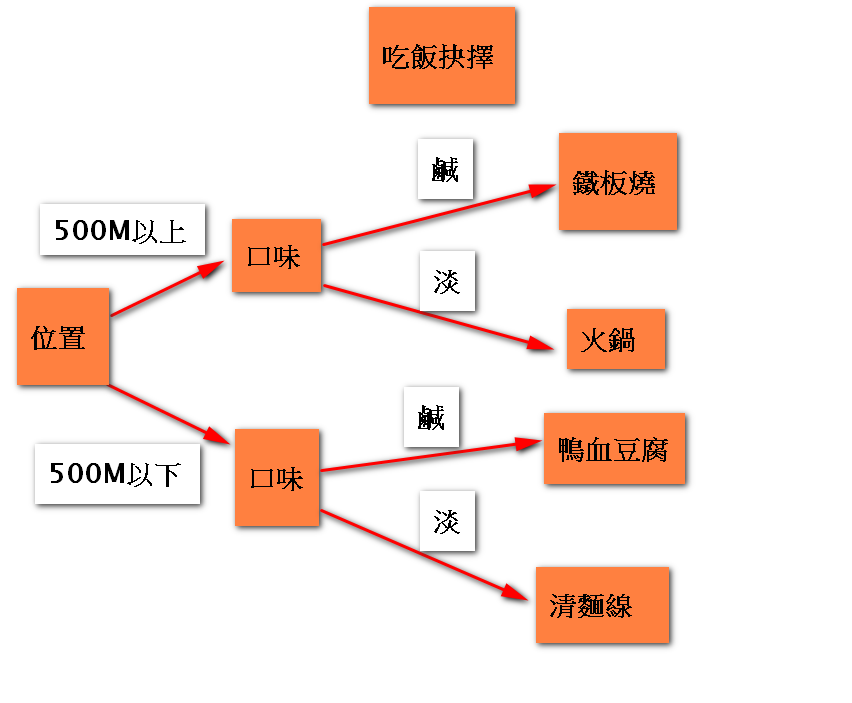
(示意圖)
所以當你今天建立好選擇標準,你在依照你今天心情(EX:我今天想要吃鹹而且你想要離家500M以內,在這個條件下,你就會選擇吃鐵板燒)
二、甚麼是隨機森林:
所以說如果你今天考慮比較多,可能覺得位置不應該是首選,可能是口味,也可能是價錢,以就是你有好幾種決定方式,這時候你就會有好幾棵樹,當樹變多時,就會成為森林,如下圖:
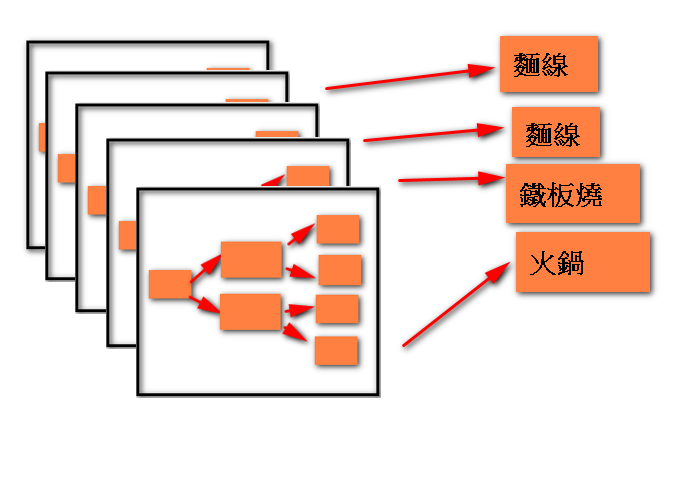
(示意圖)
而每棵樹都會給出答案,最後結果最多的就是我要的答案,而隨機森林是在從多個特徵中隨機選擇幾個特徵組成好幾棵決策樹,最後再依據各個樹給出答案再去作出選擇(若為分類資料,則用簡單多數投票方法,若為迴歸,則用平均方法)
好,今天大概把概念解釋了一下,明天就要開始實際寫algorithm
男孩把門打開往外走了出去,外面是一大片草原,空氣中混合著木棉花的香氣,而天空是一片湛藍,而前方不遠處有一大片森林,奇怪的是,附近完全沒有任何聲音,男孩只聽得到自己呼吸聲,和風吹過草地的沙沙聲,男孩沒有多想,徑直往森林走去,因為直覺告訴他,想要答案就在森林裡
--|來找我吧,我一直都在這|-- MS.CM

